
Attention-guided Network for Ghost-free High Dynamic Range Imaging (CVPR 2019) 📑

“You just want attention, you don’t want my heart” — Charlie Puth
About the paper
Attention-guided Network for Ghost-free High Dynamic Range Imaging (AHDRNet) is the current state-of-the-art in HDR image generation using bracketed exposure images. It was presented at CVPR 2019, and can be read here. The primary author, Dong Gong is a Postdoctoral researcher at The University of Adelaide. His interests include machine learning and optimization in Computer Vision.
Note: Image results, network representations, formulas and tables used in this blog post have all been sourced from the paper.
El problema
For generation of an HDR image from multi-exposure bracketed LDR images, alignment of the LDR images is very important for dynamic scenes with in-frame motion. Misalignments not accounted for before merging causing ghosting (among other) artifacts. There have been several successful (almost) attempts at compensating this motion between frames by using Optical flow estimation. As it turns out, the shortcomings of flow based methods have not served the HDR cause well.
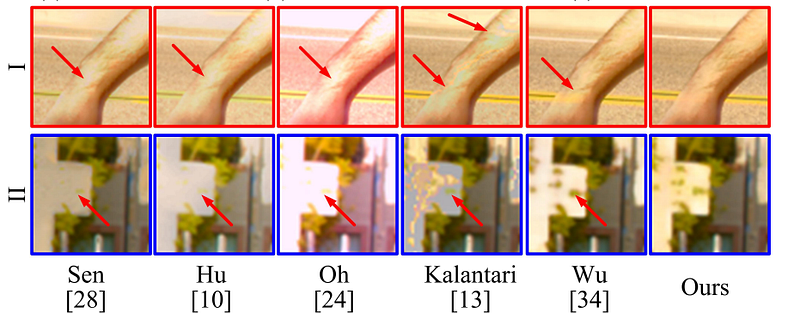
This can be seen in an attempt by Kalantari et. al, where regardless of the accurate spatial reconstruction in saturated image regions, alignment artifacts can be observed for input frames with severe motion. This can be seen in the results provided by the authors of AHDRNet in the image below. Another attempt at HDR reconstruction that targets specifically at highly dynamic LDR bracketed input (Wu et. al) claims to exploit the apparent prowess of CNN architectures in learning misalignments and compensating for the ghosting artifacts. Results presented below however show that there is scope for improvement.
Attention to the rescue
The authors propose to use attention mechanisms to solve this bi-faceted problem of reduction of alignment artifacts + accurate HDR reconstruction by using attention mechanisms. If you think about it, attention networks are just a very few Conv layers stacked together, followed (usually) by a sigmoid activation that allows the networks to focus on what’s important and pertinent to the application.

Here, the attention networks are utilised to suppress the alignment artifacts and to focus on infusing out better-exposed image regions into the generated image by attending to the spatial dynamics of the bracketed images with respect to the reference image. Regions which correspond to the reference image are highlighted, whereas regions with severe motion and saturation are suppressed. We’ll see how the attention information matrix is processed and implemented, in terms of the mathematics behind it, in some time.
The attention part of the network focuses on making decisions about which image regions contribute better to the accuracy of the network output. This is followed by a merge network that based on the attention output, tries to create HDR content from the LDR input. The better the attention mechanism, the better is the input to the merge network, thus allowing it to utilise information in the more relevant parts of the input. The merge network has been developed using dilated dense residual blocks that improve gradient-flow, hierarchical learning and convergence. The whole network is trained in an end-to-end fashion and therefore both subnetworks mutually influence each other, and learn together.
Implementation
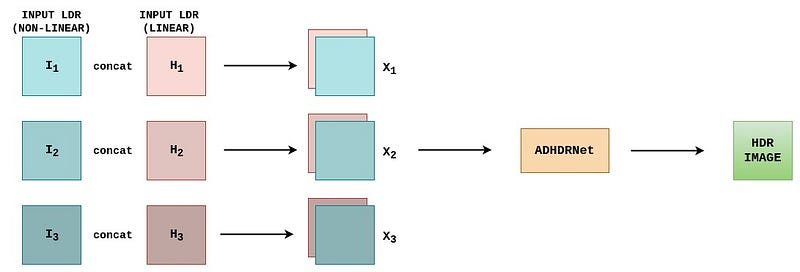
Preprocessing
The non-linear LDR input (I1, I2 , I3) is transferred to the linear domain by applying an inverse CRF (gamma correction here) and dividing by their corresponding exposure times.
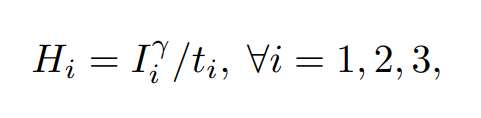
Both the linear and non-linear input (Ii, Hi) are concatenated along the channel dimensions to form Xi. X1 , X2 and X3 are fed to the network to generate the corresponding HDR output.
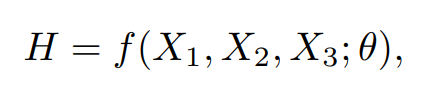
The network performs better when it has the linearised input information at its disposal. This has been observed and utilised in Kalantari et. al as well as Wu et. al.
Architecture
The whole network comprises of two sub-networks — attention network and merging network.
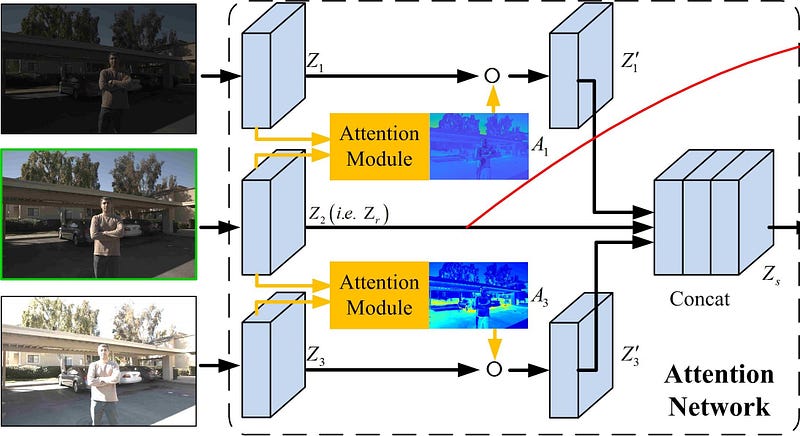
The attention network, as discussed above helps in avoiding alignment artifacts by highlighting and using information from regions in the neighbouring images (non-reference images) that correspond to the reference image. It does so in the following way.
Attention is not extracted from and applied directly to the concatenated image pairs. First the Xi s are passed through a Conv layer to extract a 64 channel feature map Zi.
Then, the reference feature map (Z2 or Zr) along with a neighbouring image feature map (Z1 and Z3) is fed into the attention module that generates an attention map to mark the important regions in the non-reference feature map with reference to Zr.
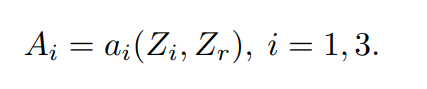
This is done for both the pairs — (Z1 , Z2) and (Z3 , Z2). This can be seen clearly in the above network representation.
Before we get into what the attention module does, let’s see what to do with the attention map that is generated. The attention map generated is essentially a 64-channel matrix that contains values between [0,1]. This matrix serves as a kind of a weight-matrix, in which each element represents the importance of a corresponding element in the feature matrix of the neighbour image, with reference to Z2. This is implemented by using the attention map generated from (Z1 , Z2) by doing an element wise multiplication of the attention map and Z1 to get Z’1.
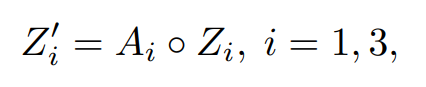
This operation results in important features (where attention is closer to 1) in Z1 getting higher numerical values and correspondingly lower values for less important features. This manifests in only important image regions from Z1 going ahead in the network to contribute to the final HDR output. The same thing happens between (Z3 , Z2) to get Z’3.
Now that we have all the input pieces most relevant to construct the HDR image, we concatenate these along the channel dimension as below -
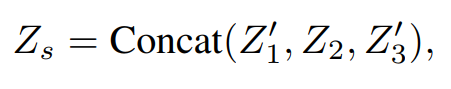
Attention module
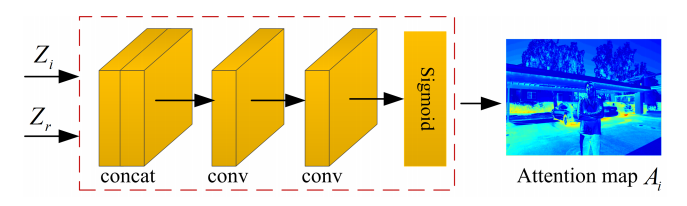
Let’s see how these attention maps are generated. The attention module used in this paper comprises of 2 Conv2d layers that output a 64-channel matrix, followed by a ReLU and a sigmoid activation respectively. It takes as input a concatenated feature vector of neighbouring and reference image (2 x 3 = 6 channels). The sigmoid activation, in the end, is used to contain the output in a [0,1] range.
Attention results

In ( a ) to ( c ), it can be observed from the results above how regions with motion discrepancies in non-reference images are suppressed (darker blue region) whereas regions that have correspondances with the reference image are highlighted (brighter blue-ish green). In ( d ) to ( f ), the regions that are better exposed in the neighbouring frames are highlighted and saturated regions are suppressed.
Merging network
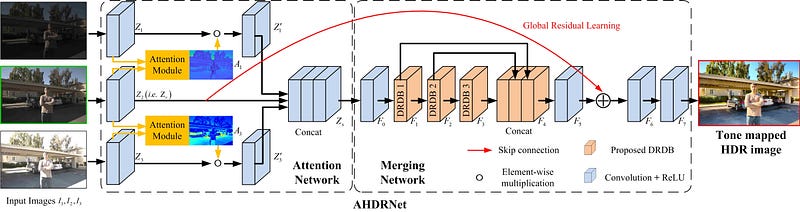
The concatenated feature map (Zs) is given as input to the merging network. The merging network used by the authors is the residual dense network proposed in Zhang et. al. Instead of the conventional Conv operations, the authors have used dilated convolutions to propagate a larger receptive field, thus calling it a Dilated Residual Dense Block (DRDB). There are 3 such blocks in the merging network that consist of dense concatenation based skip-connections and residual connections that have been proved quite effective for CNNs in solving gradient vanishing, allowing better backpropagation, hierarchical learning and therefore aiding and improving convergence performance. In the proposed AHDRNet network, each DRDB consists of 6 Conv layers and a growth rate of 32.
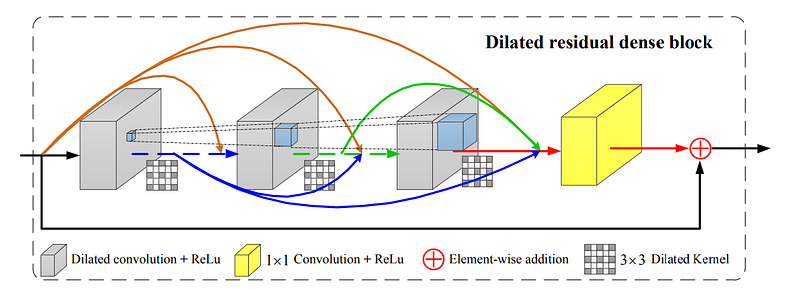
The authors have also employed local and global residual skip connections that bypass low level features to higher level ones. Local residual learning is implemented within the DRDBs whereas global residual learning is for transferring the shallow feature maps containing pure information from the reference image to the latter stages. This, and other network specifications can be observed in the merging network diagram.
Loss functions
Just like Kalantari et. al, the loss is calculated between μ-law tonemapped generated and tonemapped ground truth images. μ has been set to 5000 for all the experiments. The μ-law can be defined as -
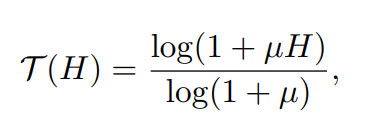
An L1 loss has been used for the same. Quantitative comparisons PSNR and HDR-VDP-2 scores presented in the paper convey that L1 loss is better at reconstructing finer details as compared to an L2 loss.
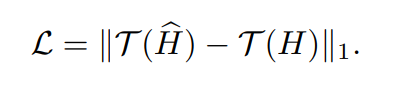
Implementation specifications
The architecture was implemented using PyTorch. The specifications and hyper-parameters are -
- Weight initialisation: Xavier
- Optimizer: ADAM
- Learning rate: 1 x 10–5
- Batch size: 8
- GPU: NVIDIA GeForce 1080 Ti
- Inference time for 1 image (1500x1000): 0.32 sec
Results
The networks were trained and tested on the datasets provided by Kalantari et. al. The authors have provided quantitative and qualitative comparisons between several variants of the network, in terms of PSNR and HDR-VDP-2 scores.
- AHDRNet — The full model of the AHDRNet.
- DRDB-Net (i.e. AHDRNet w/o attention)
- A-RDB-Net (i.e. AHDRNet w/o dilation)
- RDB-Net (i.e. AHDRNet w/o attention and dilation)
- RB-Net (i.e. AHDRNet w/o attention, dilation and dense connections). DRDBs replaced by RBs.
- Deep-RB-Net. More RBs are used.
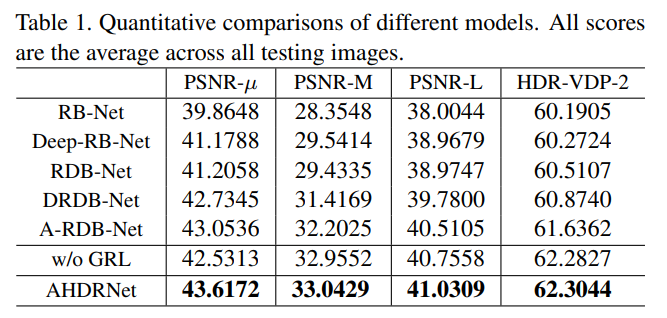
The results show how each component of the AHDRNet is important to the efficacy of the whole network i.e. attention is important, dilated convolutions are important, dense connections are important and residual learning is important.

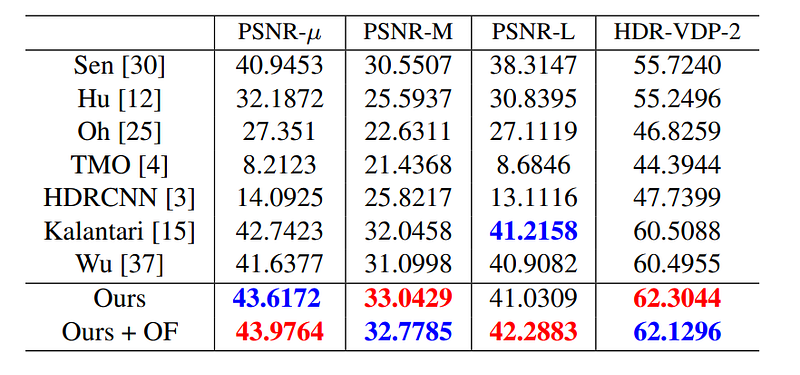
Comparison with state-of-the-art
Comparisons with current state-of-the-art approaches (learning based and non-learning based) reveal how AHDRNet beats existing approaches. The closest competitor is obviously Kalantari et. al’s implementation that comes only second to AHDRNet. The authors have also provided the results of a variant of AHDRNet that uses Optical-flow aligned images (AHDRNet + OF).
The visual results show the efficacy of the network in infusing meticulous details in the generated HDR output without giving rise to any alignment artifacts even in cases of severe motion. Here are some of the results, taken from the paper -


Conclusion
AHDRNet is the first attention-based approach to solving the problem of HDR image generation. The finesse of attention mechanisms has been utilised to align the input LDR images. Previous attempts at image alignment have used Optical flow-based methods, which have some inaccuracies and do not perform well for severe motion between frames. An attention-based approach however performs exceedingly well in terms of HDR reconstruction as well as in removing alignment artifacts. Extensive experiment reveal how AHDRNet supersedes existing approaches qualitatively and quantitatively, and that it has become the new state-of-the-art in HDR image generation.
References
- Qingsen Yan, Dong Gong, Qinfeng Shi, Anton van den Hengel, Chunhua Shen, Ian Reid, Yanning Zhang, Attention-guided Network for Ghost-free High Dynamic Range Imaging (2019), CVPR 2019
- N. K. Kalantari and R. Ramamoorthi, Deep high dynamic rangeimaging of dynamic scenes (2017), ACM Trans. Graph
- Shangzhe Wu, Jiarui Xu, Yu-Wing Tai, and Chi-Keung Tang, Deep high dynamic range imaging with large foreground motions (2018), European Conference on Computer Vision (ECCV), September 2018

